|
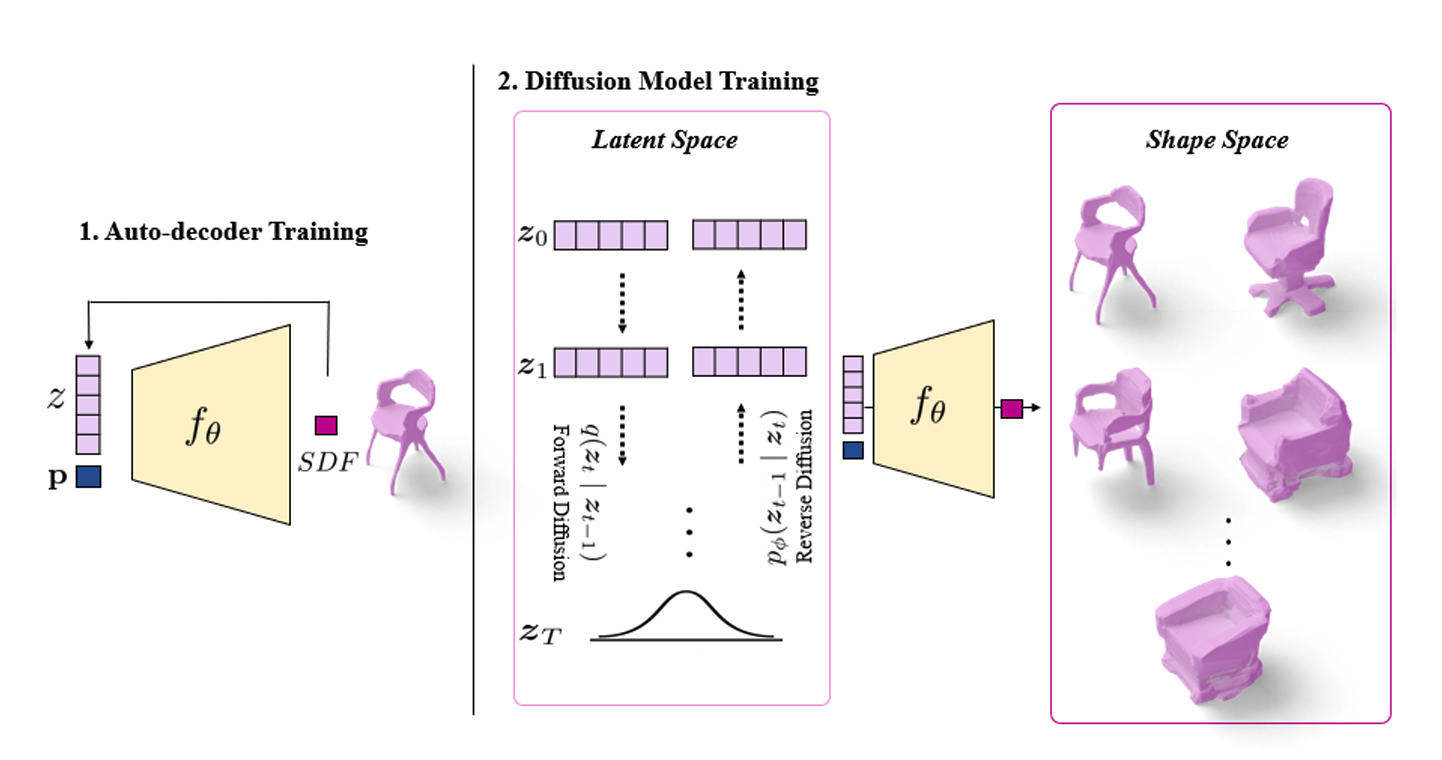
Diffusion models have shown great promise for image generation, beating GANs in terms of generation diversity, with comparable image quality. However, their application to 3D shapes has been limited to point or voxel representations that can in practice not accurately represent a 3D surface. We propose a diffusion model for neural implicit representations of 3D shapes that operates in the latent space of an auto-decoder.
This allows us to generate diverse and high quality 3D surfaces. We additionally show that we can condition our model on images or text to enable image-to-3D generation and text-to-3D generation using CLIP embeddings. Furthermore, adding noise to the latent codes of existing shapes allows us to explore shape variations.
|